我們在前面的寫給MLOps人才培育苦手談論到MLOps是一個需要大家通力合作的一項專案,除了該專案帶來資訊和商業的影響力,在技術上也屬於比較前緣、大部分的團隊都還在摸索的階段。今天想來談一談DevOps在MLOps當中的角色,ML團隊可以怎麼樣的更好跟DevOps團隊溝通。
一個DevOps的養成如果要談的話可能三天三夜都講不完,如果以四個字來說:包山包海。如果以一句話來說,則是"精通部署、系統監測、開發以及產品環境維護、資源和數據管理、安全等方面的開發人員"。如果想學習更多的DevOps知識可以參照大衛和牛的文章。
Ankit Jain 提到一句話,我覺得可以用來區分DevOps和資料科學家的工作心法。 "把Pipeline視為一個產品,而不只是把模型視為一個產品。" 在資料科學家的養成當中,有非常多的時間跟心力在討論,關於演算法怎麼選擇、演算法細節怎麼實踐、資料怎麼採樣、資料怎麼載入、模型怎麼驗證等等。這些談話內容都是圍繞在模型上面。但是以實際面來說,模型只佔了非常小的一部分,甚至當模型上線之後,專案的花費除了當初訓練的費用之外,還包含服務本身部署的機器上,模型訓練所使用的時間、金錢等資源可能只佔據了整個開發循環的10%左右。
而DevOps是怎麼看ML產品的?這可以從他們日常的工作當中窺見一二。今天不論是資料庫、一個購物車網站、一個約會網站、或是具有ML功能的影音串流網站,這些服務在DevOps的眼中,就是大小不同、重量不同的積木們堆疊在一起。DevOps的工作就是確保這些積木們,都有足夠的資源可以使這些服務可以運作良好。像是在使用者還沒感受到不耐煩的時間內回覆使用者、乘載不同量級的使用者需求等等。也確保這些積木們彼此之間的通路是具有安全性的,只有被授權的人可以拜訪某些服務,DevOps有一大部分的工作也是確保各個服務之間溝通合乎系統規範,有使用安全鑰匙、並且定期更新這些鑰匙。所以當DevOps在看ML產品的時候,他們其實不會很在乎模型的準度,反倒是很在乎,誰可以使用到這個服務、有多少人會來使用者個服務、在模型更新的時候是不是也會使用CI/CD更新、需不需要在團隊裡面做權限設定等等。
倘若讓ML團隊自己架設與設置開發跟部屬的環境,對於DevOps團隊來說會是非常頭痛的事情,安全性與合規性跟公司其他系統都不一致。一般常見的分工配置,如以下的圖所示:

(a. 圖左)公司有一個中心的DevOps團隊,負責支援各個開發團隊的部署以及開發環境。通常在ML專案建立的初期,會需要有一個或兩個人力,一週五天專職負責ML專案的DevOps相關設置。這跟過去一個DevOps可能一兩天就用其他專案的模板,套用在其他軟體專案的情況相較不同。舉例來說,可以看一下kubeflow的部署yaml,感受一下假若全自架一個ML系統需要的資源以及權限有哪些。
(b. 圖右)開發團隊是跟公司的產品互相綁在一起的,也就是說每個產品都有自己的開發人員、ML團隊、DevOps團隊,在這樣的狀況下,可能各產品的設置都不太ㄧ樣。公司可以討論是否要建立一個資料、ML的中心平台,也就是圖當中的另一種定義的核心團隊(Core team),讓不同產品的ML團隊可以上去使用,或是各產品之間獨立開發。無論是否要設置一個統一的平台,建議不同產品之間的ML專案設置仍然可以互通有無,不必在公司裡面重複製造輪子。
無論是這兩種團隊設置的哪一種,公司也必須要從人力資源的管理上去思考,在ML專案上的所有系統需求是否都是要自家開發團隊維護。如果公司的DevOps資源真的不足夠,發現自己管理各項服務的成本太高,也可以把專案的資源內容多使用各家雲服務公司所提供的產品,減少許多公司內部的營運成本。這並不代表完全不需要DevOps了,還是會需要在網路安全、角色授權、安全鑰設定、負載管理等地方需要DevOps團隊的支援。
DevOps的加入所帶來的影響:可以讓ML團隊的程式碼,必須要能夠朝更自動化的方向去維護。也讓整個開發流程更穩健。其中包含更好的系統負載(包含CI/CD、IaC、監控),以及更好的安全性。
CI與CD的基礎,會是從版本控制、使用Git開始談。ML專案當中,需要進版本控制的東西會有:(1)資料處理:資料處理前後的狀態(2)訓練模型:模型框架、超參數的設置、訓練的時間以及使用的機器規格、模型版本(3)發佈模型:發佈的版本、時間、是誰授權、發佈到哪些環境、是否有導流的參數配置(A/B test)。
建立基本的版本控制設定之後,也包含建立模型與部屬模型的兩個建構pipeline。一個專注在模型的建立、訓練、註冊模型。另一個則是專注在部屬的行為,團隊中誰會去檢視訓練結果、部署到哪一個環境。在這兩個pipeline的設置,也都需要設置相對應的測試與驗證,確保程式碼以及相關資料的品質。
在持續整合的部分在一開始會有點零散,因為資料的來源可能不是單一來源、資料的格式可能來自結構與非結構的來源、不同階段專案使用的特徵與演算法版本管理、需要儲存的特徵值可能為使用者即時產生的,或是之後要一次存取的離線特徵等等。但是在經過幾次的迭代之後,團隊也能漸漸抓到合作、版本更迭的方式。
在部署的部分目前都傾向讓ML專案本身有一個後端server,與模型互動,而模型本身成為一個微服務,便於可擴展性。在部屬的過程也須考慮當前版本是否跟其他版本進行A/B Test,確保與模型互通的客戶旅程配置。
在持續部署上,DevOps也需設定不同環境,供ML團隊,以及ML功能整合的產品團隊一起測試。舉例來說,電商平台上的推薦系統,確保電商平台在staging上能夠與在staging上的推薦系統互動,且獲得預期結果。
這些測試以及預熱、負載測試都能夠讓產品能夠無痛的上線。同時也包含上線之後的故障排除與回溯之前的部屬版本。
在訓練模型的過程當中,對資料來源的前處理、重新訓練、使用機器以及評估模型這些設定,在過去可能都內嵌在程式碼裡面。現在則需要抽出來,讓這些設定可以透過yaml檔注入服務,讓訓練及部署的自動化程度更提高。也因為這個部分使得ML專案學習到其他軟體專案的特性,讓專案本身更容易範本化,長遠來說也助於公司快速展開下一階段的測試及市場擴張。
日誌的重要性,大概可以不必再重申。通常公司各個系統的日誌,都會統一導流到一個集中的地方,像是Grafana、CloudWatch等,方便DevOps查找。同樣的ML專案也需要注意的部分,也是要如何讓日誌輸出到系統收集日誌的收集點,方便統一導向公司的dashboard。
除此之外,也可以設置一些通知,例如說模型訓練完成、測試完成,或者發現模型服務無法被正常呼叫、模型準確度突然驟降等等,都可以設置相對應的通知訊息到信箱、Slack、或其他公司內部使用的通訊軟體。借助 MLOps 監控,團隊可以花相對少的力氣部署和管理數千個模型,這讓過去ML團隊只能管理少數模型的通點能夠被解決。
上次在安全與合規性提到的那5點可以再複習一次,同樣也是DevOps同事們流血流淚幫忙把關的!!!
在了解DevOps在專案當中的角色之後,資料科學家若想要學習跟部屬相關的知識,也可以參考以下的MLOps Basics專案。
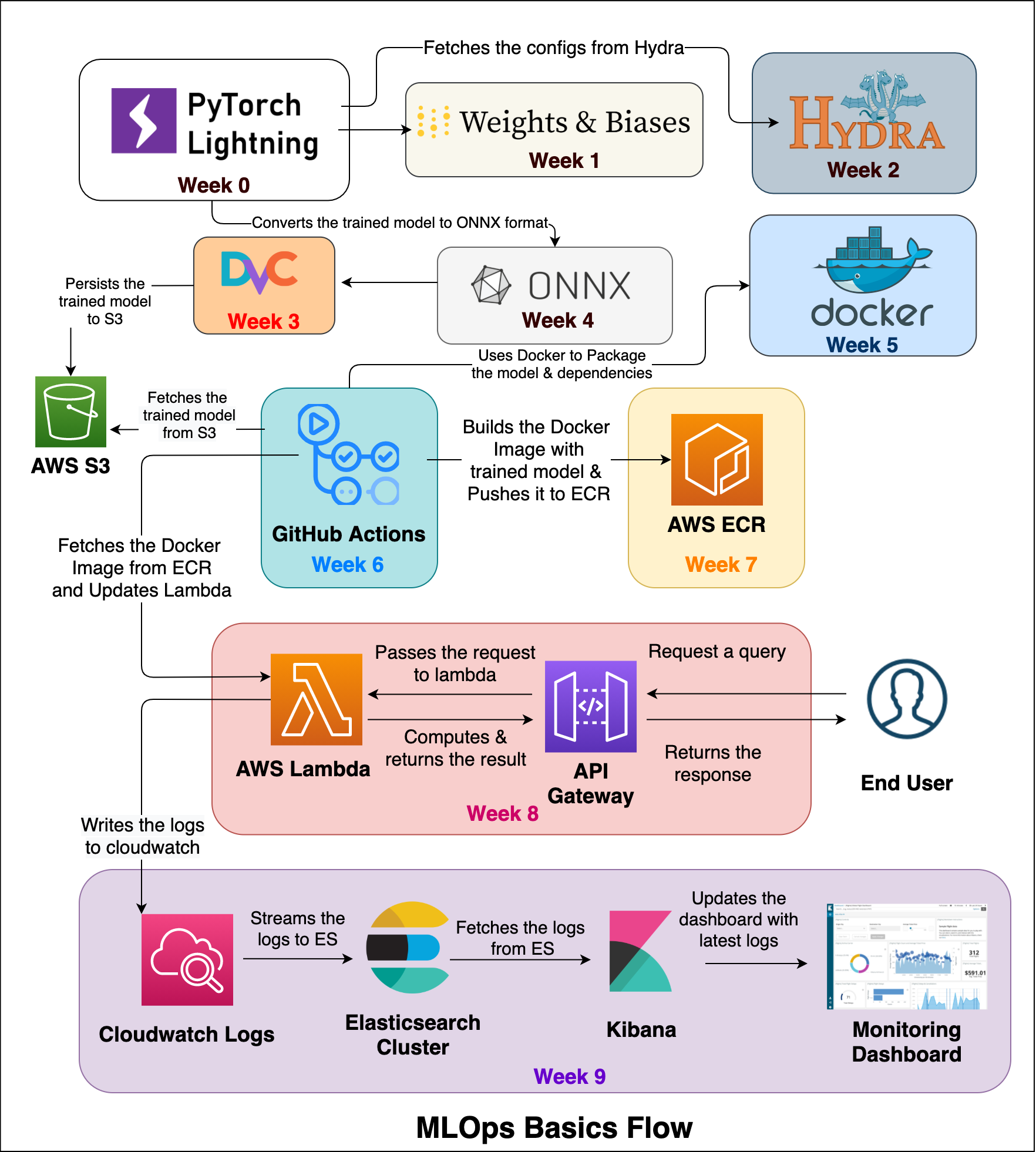
最近在Github上看到這個MLOps Basics專案,發現是對資料科學家了解產品部署上面一個蠻完整的教學,其中包含config設定、轉換模型格式,讓模型可以更輕易地部署到容器、邊緣設備等。也包含版本控制、容器的使用、Github action的使用(學習簡單的CI)、與其他serverless服務互動以及如何看日誌(log)。在學習的過程當中,也可以上網找相關資料、或者跟團隊的DevOps請教其中一些跟產品部署相關比較陌生的概念。
在這邊簡單列出幾個談論MLOps會使用到服務,之後可以再延伸討論細節:
(1)版本控制:DVC
(2)資料處理:Airflow
(3)模型管理:MLflow
(4)ML平台:Kubeflow、SageMaker
(5)模型解釋:SHAP
(6)模型服務:Seldon、KfServing、TFServing
有興趣也可以到MLOps Resources看看其他相關資源。
若要總結關於DevOps在MLOps的角色,那麼唯一的建議就是,儘早讓資料科學家與DevOps一起討論專案的規劃。 不管是資料科學家或者DevOps都需要從自己的舒適圈邁出,彼此學習對方工作的思考模式以及溝通的語言、專有名詞等。
資料科學家必須學習一個軟體交付週期應該會走過的階段、該注意的事情。而DevOps也需要學習ML專案和其他專案的相同以及相異處,ML專案在資源的配置上或是部署平台的維護也相較其他專案複雜,在一開始的時候也無法用其他軟體專案的範本直接應用在ML專案。
不管你是來自團隊的哪一方,開始花點時間去看看對方的工作內容,問問對方最近在煩惱的技術與非技術的問題等等,這都會對於團隊的溝通、合作有很大的助益。
今天先談到這邊了,明天見。
Reference
本篇相關Reference都已放在文章中的連結。

